C++ (with STL Data Structures and Algorithms) Notes for Interview
Foreword
I have been wanting to become a game developer since I studied and tried some directions in Computer Science during my bachelor’s study. The idea behind this is that even if I cannot get away with programming, at least I could work on something that I love. However, this is a start of a nightmare until now. I found there is just so much to learn in order to just get a job in the game industry.
Thus, I decided to document what I learned as a reference for later review, and as a record of my growth. All those things start with this summary of C++. If you are reading this, I would assume you already have some background knowledge about programming, as the content won’t begin with very basic knowledge. I would be glad if you find this blog helpful!
Polymorphism and Virtual Function
Polymorphism
Polymorphism is one of the most vital features of Object-Oriented Programming. The so-called polymorphism means that a function of the same name has multiple states, or an interface has different behaviors. C++ polymorphism is divided into compile-time polymorphism and run-time polymorphism.
- Compile-time polymorphism is called static binding. It is realized by function (including operator) overloading and templates.
- Run-time polymorphism is called dynamic binding. It is realized through inheritance and virtual functions.
Virtual Function
Virtual function is one of the methods of realizing polymorphism in C++ language. By pointing to the base class pointer or reference of the derived class, you can access the overridden member function with the same name in the derived class. When accessing a member function of a class through a pointer:
- If the function is a non-virtual function, the compiler will find the function according to the type of the pointer; that is, the function of the pointer’s class will be called.
- If the function is a virtual function, and the derived class has a function with the same name to override it, then the compiler will find the function according to the pointer; The reason why the compiler can find the virtual function through the object pointed to by the pointer is because the virtual function table is additionally added when the object is created. If there is a virtual function in a class, an additional array will be added when creating an object of this class, and each element in the array is the entry address of the virtual function. However, the array and the object are stored separately. In order to associate the object with the array, the compiler also inserts a pointer in the object to point to the starting position of the array. The array here is the virtual function table (virtual function table), abbreviated as vtable. See the following image:
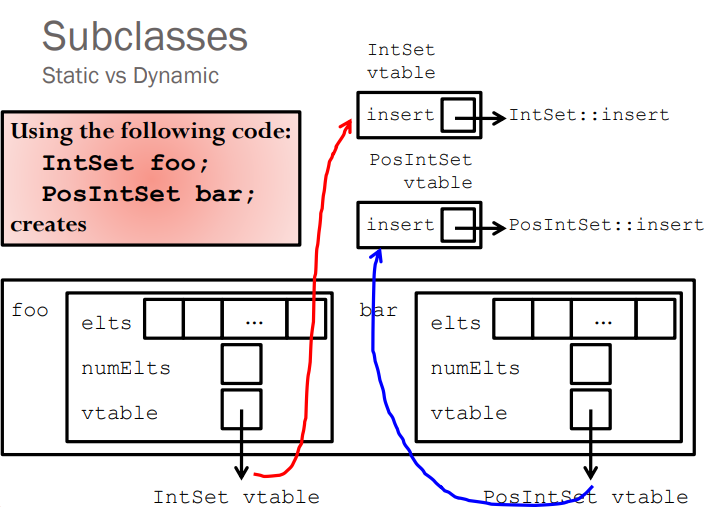
- The call of the virtual function is determined at runtime by looking up the function address in the virtual function table.
- Virtual functions exist in classes, and different class objects share a virtual function table (in order to save memory space).
Can constructors and destructors be virtual?
No.Virtual function calls are looked up through the virtual function table. But the virtual function table is pointed to by the vptr pointer of the instantiated object of the class. The vptr is stored in the internal space of the object. The constructor needs to be called to complete the initialization. If the constructor is a virtual function, then you need to find vptr to call the constructor, but vptr has not been initialized yet!
What about destructor?
The destructor needs to be a virtual function! If the destructor is not a virtual function, only the base class will be released when deleting, and there is a risk of memory leaks. (Conversely, call the derived class destructor first, then call the base class destructor)
Memory Management
C++ Memory Layout
| Memory Layout |
|---|
| Stack |
| for Stack and Heap |
| Heap |
| BSS |
| Data |
| Text |
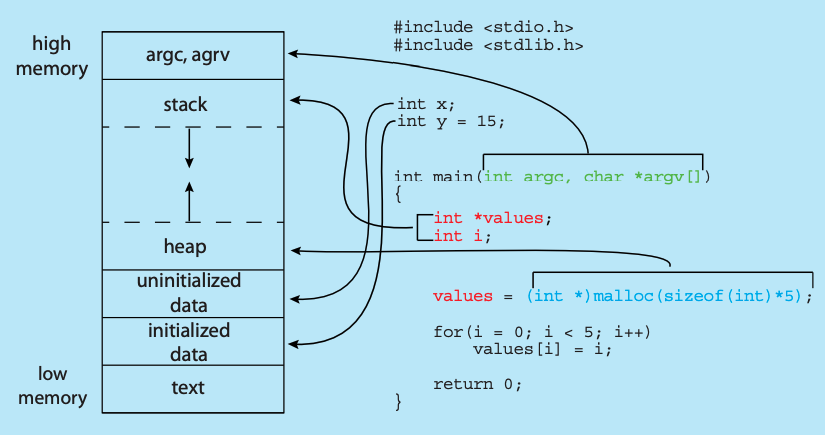
- Text: This segment is read-only and allocated by codes when a process starts up. Text segment is sharable and hence only a single copy exists as well as read-only.
- Data: This segment contains uninitialized global and static variables that are initialized. It is readable/writable.
- BSS (Block Started by Symbol): This segment contains initialized global and static variables that are initialized. It is readable/writable.
- Heap: This segment is used for dynamic memory allocation using
malloc() / newand should be de-allocated byfree() / delete(of course readable/writable). It is shared in all threads. - Stack: This segment contains non-static local variables. The virtual pointer is also stored here. Stack Frame: A set of values pushed for one function call is called Stack Frame (i.e. recursive function).
A more clear memory layout of a C program:
C++ Memory Alignment
The reason for memory alignment: The key lies in the efficiency of CPU access to data. In order to improve efficiency, the computer fetches data from memory according to a fixed length. For example, on a 32-bit machine, the CPU fetches 32bit data every time, which is 4 bytes. Thus, the sizeof for a struct/class is not always equal to the sum of sizeof of each individual member.
Rules:
- The first address of
structcan be divisible by the size of its widest basic type member. - The offset relative to the starting address of each member in the structure can be divisible by the size of the variable.
- The overall size of the structure can be divisible by the widest member size; if these conditions are not met, the compiler will perform a padding.
Different compilers might have different alignment constraints as C standards state that alignment of structure totally depends on the implementation.
Examples:
struct A {
int x; // 4 bytes
// Padding of 4 bytes
double z; // 8 bytes
short int y; // 2 bytes
// Padding of 6 bytes
}; //sizeof(A) = 24
struct B {
short s; // 2 bytes
int i; // 4 bytes
char c; // 1 byte
}; //sizeof(B) = 12
struct C {
int i; // 4 bytes
short s; // 2 bytes
char c; // 1 byte
}; //sizeof(C) = 8
The size of the class is similar to the struct with little difference.
- Empty class has size 1 (byte).
- The virtual function pointer has size of 4 bytes.
- The size of sub-class is equals to the size of all members plus the size of its parent class. (Note that they share the virtual function pointers)
For modern C++, the alignas type specifier is a portable, C++ standard way to specify custom alignment of variables and user defined types. The alignof operator is likewise a standard, portable way to obtain the alignment of a specified type or variable. An example is shown below:
// Reference: https://learn.microsoft.com/en-us/cpp/cpp/alignment-cpp-declarations?view=msvc-170
#include <iostream>
struct alignas(16) Bar
{
int i; // 4 bytes
int n; // 4 bytes
alignas(4) char arr[3];
short s; // 2 bytes
};
int main()
{
std::cout << alignof(Bar) << std::endl; // output: 16
}
Type Casting
Type casting refers to the conversion of one data type to another in a program. Type Casting is divided into two types: Implicit conversion or Implicit Type Casting and Explicit Type Conversion or Explicit Type Casting.
Implicitly type casting automatically converted from one data type to another without any external intervention such as programmer or user. It means the compiler automatically converts one data type to another. Example here:
int num = 20;
char ch = 'a';
int res = 20 + 'a'; //res = 117 since 'a' is 20
Basic explicit type casting is like int num = 5; float x = float(num);, which is intuitive. To deal with more complex data structure, C++ offers 4 different cast operators: static_cast, dynamic_cast, const_cast, reinterpret_cast.
-
static_cast: It can realize conversion between built-in basic data types in C++, such as enum, struct, int, char, float, etc. It can perform upward type conversion and downward type conversion between class levels (downward is not safe because no dynamic type checking is done). It cannot perform conversions between pointers of unrelated types (such as non-base classes and subclasses), nor can it act on objects containing underlying const. “Static” means it runs at compile time. -
dynamic_cast: It can safely convert the pointer or reference of the base class to the pointer or reference of the derived class (upward conversion is also possible), if the pointer conversion fails, return NULL, and if the reference return fails, a bad_cast exception is thrown.dynamic_castruns a security check at runtime; the parent class ofdynamic_castmust have a virtual function, otherwise the compilation will fail. Example:
class parent {
public: virtual void print()
};
class derived: public parent { };
int main () {
parent *ptr = new derived; // create an object ptr
// use the dynamic cast to convert class data
derived* d = dynamic_cast <derived*> (ptr);
// check whether the dynamic cast is performed or not
if(d != NULL)
cout << " Dynamic casting is done successfully";
else
cout << " Dynamic casting is not done successfully";
// Output: " Dynamic casting is done successfully"
}
reinterpret_cast: It can convert convert a pointer to any other type of pointer whether the given pointer belongs to each other or not. And it can also convert any built-in data type to any other data type, even between an integer to a pointer. Example:
int main(){
int *pt = new int(65);
int *ch = reinterpret_cast<char *>(pt);
cout << ch << " " << *ch;
return 0;
}
// Output: A A
const_cast: It can convert const to non-const (or vice versa).const_castcan only be used for pointers or references, and can only change the underlying const of the object.
int main(){
const int a1 = 10;
const int *b1 = &a1;
int *d1 = const_cast<int *>(b1);
*d1 = 15; // invalid operation
int a2 = 10;
const int *b2 = &a2;
int *d2 = const_cast<int *>(b2);
*d2 = 15; // valid operation
return 0;
}
Smart Pointer
Smart pointers mainly solve the problem of memory leak by automatically releasing memory space. Because it is a class itself, the destructor will be called when the function ends, and the memory space will be released by the destructor. There are 3 different types of shared pointers: shared_ptr, unique_ptr and weak_ptr. Header file: <memory>.
-
shared_ptr: Multiple shared pointers can point to the same object. Using the mechanism of reference counting, when the last reference is destroyed, the memory space is released. Whenever possible, use themake_sharedfunction to create ashared_ptrwhen the memory resource is created for the first time.make_sharedis exception-safe. It uses the same call to allocate the memory for the control block and the resource, which reduces the construction overhead. Otherwise, you have to use an explicitnewexpression to create the object before you pass it to theshared_ptrconstructor. -
unique_ptr: This ensures that only one smart pointer can point to the object in the same period of time (the unique_ptr can be passed through the move operation), and cannot be copied. -
weak_ptr: This is used to solve the deadlock problem whenshared_ptrrefers to each other. If twoshared_ptrrefer to each other, then the reference count of these two pointers can never drop to 0, and the resource will never be released. If it is a weak reference (weak_ptr) to the object, it will not increase the reference count of the object, and it can be converted toshared_ptr,shared_ptrcan be directly assigned to it, and it can obtainshared_ptrby calling the lock function.
Example of smart pointers:
#include <iostream>
using namespace std;
#include <memory>
class Rectangle {
int length;
int breadth;
public:
Rectangle(int l, int b){
length = l;
breadth = b;
}
int area(){ return length * breadth; }
};
int main(){
// Unique Pointer
unique_ptr<Rectangle> P1(new Rectangle(10, 5));
cout << P1->area() << endl; // This'll print 50
// or unique_ptr<Rectangle> P2(P1);
unique_ptr<Rectangle> P2;
P2 = move(P1);
cout << P2->area() << endl; // This'll print 50
// Shared Pointer
shared_ptr<Rectangle> P3 = make_shared<Rectangle>(10, 5);
cout << P3->area() << endl; // This'll print 50
shared_ptr<Rectangle> P4;
P4 = P3;
cout << P4->area() << endl; // This'll print 50
// Weak Pointer
weak_ptr<Rectangle> P6;
auto test = [] (weak_ptr<Rectangle> P){
if(auto temp = P.lock()){
cout << temp->area() << endl;
}
else{
cout << "expired!" << endl;
}
};
{
auto P5 = make_shared<Rectangle>(10, 5);
P6 = P5;
test(P6); // This'll print 50
}
test(P6); // This'll print expired!
return 0;
}
lvalues, rvalues and Copy Constructor
lvalues and rvalues
- An lvalue is an addressable storage unit whose value can be changed by the user, such as a common variable: an int, float, class, etc. The lvalue has a persistent state and is not destroyed until it leaves the scope.
- The rvalue represents a temporary object that is about to be destroyed and has a short-lived state, such as the literal value constant “hello”, the expression int func() that returns a non-reference type, etc., will yields an rvalue.
- An rvalue reference is a reference that must be bound to an rvalue, which can be obtained by
&&. An rvalue reference can only be bound to an object that is about to be destroyed, so it can be moved freely its resources; - An rvalue reference is a concept introduced to support move operations. It can only be bound to an object to be destroyed. Move operations using rvalue references can avoid unnecessary copying and improve performance. Use the
std::move()function to convert an lvalue to an rvalue reference.
Simple example:
int main(){
int i, j, *p;
// Correct usage: the variable i is an lvalue and the literal 7 is a rvalue.
i = 7;
// Incorrect usage: The left operand must be an lvalue (C2106).`j * 4` is a rvalue.
7 = i; // C2106
j * 4 = 7; // C2106
// Correct usage: the dereferenced pointer is an lvalue.
*p = i;
// Correct usage: the conditional operator returns an lvalue.
((i < 3) ? i : j) = 7;
// Incorrect usage: the constant ci is a non-modifiable lvalue (C3892).
const int ci = 7;
ci = 9; // C3892
}
Constructor, Deep Copy and Shallow Copy
-
The role of the copy constructor is to define what we do when we initialize this object with another object of the same type. In some cases, if we do not define the copy constructor ourselves, the default copy constructor is used, an error will occur. For example, if there is a pointer in a class, if the default copy constructor is used, the pointer will be copied, that is, the two pointers point to the same object, then after one of the class objects is destructed, the pointer will also be deleted, and the other A pointer in a class will become a dangling pointer;
-
Shallow copy simply and directly copies the pointer to an object without copying the object itself. The old and new objects still share the same memory. However, deep copy will create an identical object. The new object does not share memory with the original object, and modifying the new object will not change the original object.
Standard Template Library (STL), Data Structure and Algorithms
What is STL?
The Standard Template Library (STL) is a set of C++ template classes to provide common programming data structures and functions such as lists, stacks, arrays, etc. It is a library of container classes, algorithms, and iterators.
- Containers or container classes store objects and data.
- Sequence Containers: implement data structures which can be accessed in a sequential manner. (vector, list, deque, etc)
- Container Adaptors : provide a different interface for sequential containers. (queue, stack, etc)
- Associative Containers : implement sorted data structures that can be quickly searched (O(log n) complexity). (set, map, multiset, etc)
- Unordered Associative Containers : implement unordered data structures that can be quickly searched. (unordered_set, unordered_multiset, unordered_map, all introduced in C++11)
-
Algorithms are a collections of implemented functions that operate on containers. For example, there are sorting and searching functions like
sort()andbinary_search(). - Iterators are used to point at the memory addresses of STL sequence containers.
vector<int> ar = { 1, 2, 3, 4, 5 };
vector<int>::iterator ptr = ar.begin();
- Functors are objects that can be treated as though they are a function or function pointer.
// this is a functor
struct add_x {
add_x(int val) : x(val) {} // Constructor
int operator()(int y) const { return x + y; }
private:
int x;
};
// Now you can use it like this:
add_x add42(42); // create an instance of the functor class
int i = add42(8); // and "call" it
assert(i == 50); // and it added 42 to its argument
Basic Data Structures in STL
Two images below offer a clear view of data structures in STL.
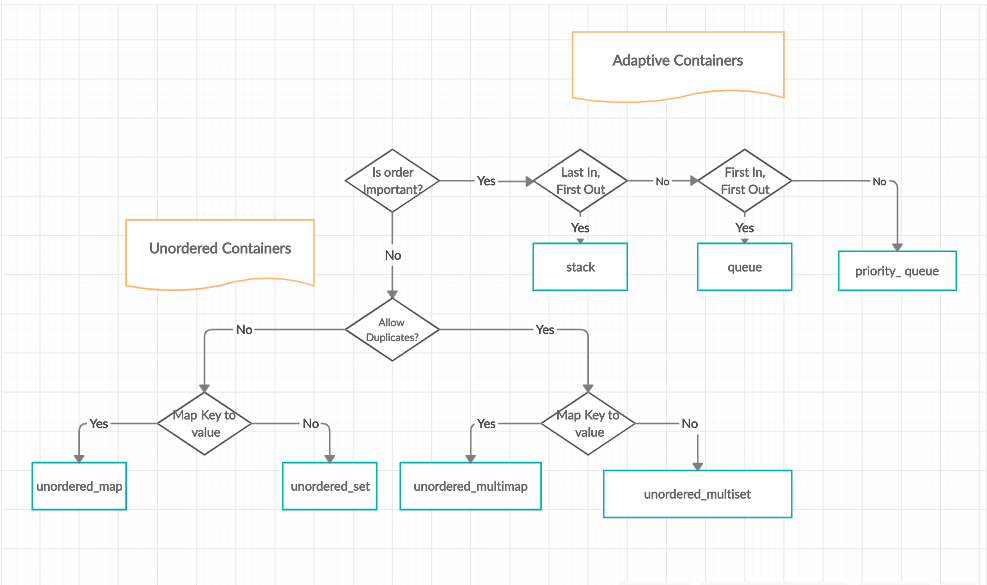
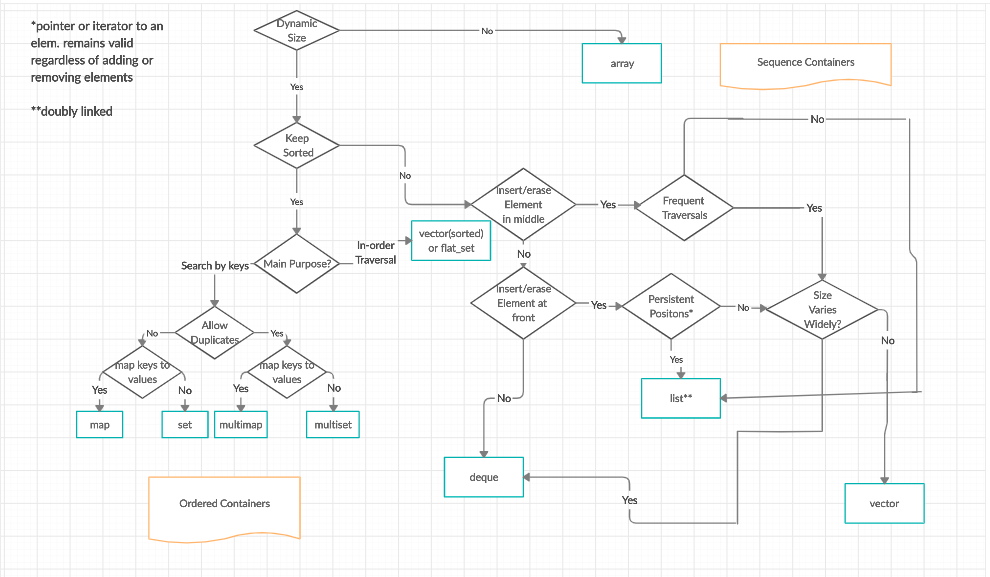
How are the STL containers implemented?
-
vector, the bottom layer is an array with continuous memory. The core of vector is that its length is automatically variable. Vector is mainly completed by three iterators (pointers): start pointing to the first element, finish pointing to the tail element, and end_of_storage pointing to the end of the memory. The expansion mechanism of vector is: when the current available space is insufficient, allocate twice the current space or the current space plus the required new space size (whichever is larger). -
list, the bottom layer is a circular double linked list. The linked list nodes and the linked list are defined independently, and the nodes contain pre, next pointers and data. -
deque, a two-way queue, is composed of segmented continuous spaces, and each segment of continuous space is a buffer, controlled by a central controller. It must maintain a map pointer (controller pointer), and also maintain two iterators start and finish, pointing to the first buffer and the last buffer. Deque can be expanded at the front end or at the back end, and these pointers and iterators are used to control jumps between segment buffers. -
stackandqueue. They are all implemented bydequeas the underlying container. They are a kind of container adapter that modifies the interface ofdequeand has its own unique properties.stackseals the head end of the deque, thus it is first in last out.queueis a deque that seals the tail end, thus it is first in first out. -
priority_queueuses vector as the underlying container and heap as the processing rule. The essence of heap is a complete binary tree. -
setandmap. The bottom layer is implemented by red-black tree. A red-black tree is a binary search tree, but it has an additional color attribute. The properties of the red-black tree are as follows:- each node is either red or black;
- the root node is black;
- if a node is red, then its child nodes are black;
- any node The number of black nodes contained in the path from the point to the end of the tree (NULL) must be the same.
Through the constraints defined above, the red-black tree ensures that no path will be more than twice as long as the other paths; therefore, the red-black tree is a weakly balanced binary tree, relative to the balanced binary tree that strictly requires balance, its number of rotations Less, so for the case of more insertion and deletion operations, red-black trees are usually used.
What is the time complexity of the search, insert and delete operation of those containers?
-
vectorVector supports random access (by index), and the time complexity is O(1). If it is an unordered vector, the time complexity of searching is O(n), if it is an ordered vector, using binary search is O(log n). For the insertion operation, the insertion at the tail is the fastest, followed by the middle, and the head is the slowest, and the deletion is the same. The memory occupied by vector is relatively large, because the double expansion mechanism may lead to waste of memory. -
listSince the bottom layer of the list is a linked list, it does not support random access and can only be searched by scanning. The complexity is O(n). But the insertion and deletion are fast, and only need to adjust the pointer. list does not cause memory waste and occupies less memory. -
dequeDequeue supports random access, but its performance is lower than that of vector (still O(n)). It supports double-ended expansion, so inserting and deleting elements at the head and tail is very fast, which is O(1), but inserting and deleting elements in the middle is very slow. -
setandmapThe bottom layer is implemented based on red-black tree, the time complexity of adding, deleting, checking and modifying is approximately O(log n), and red-black tree is implemented based on linked list, so it occupies less memory. -
unordered_setandunordered_mapThe underlying layer is implemented based on a hash table and is unordered. Theoretically, the time complexity of adding, deleting, checking and modifying is O(1) (the worst time complexity is O(n)). In fact, whether the data distribution is even or not will greatly affect the performance of the container.
Hash Table
Notice that the unordered_set and unordered_map are based on hash table, to better understand this, we now take a closer look at it.
The hash table stores elements in key-value pair. Key is the unique integer that is used for indexing the values. Value is the data that are associated with the corresponding key.
Hash function
In a hash table, a new index is processed using the keys. And, the element corresponding to that key is stored in the index. This process is called hashing.
A good hash function may not prevent the collisions completely however it can reduce the number of collisions. For example:
- Hashing by modulo:
h(k) = k % m;for k is a key and m is the size. - Hashing by multiplication:
A = (sqrt(5) - 1)/2;
// we define that kA % 1 gives the fractional part kA.
h(k) = floor(m * ((k * A) % 1));
Hash Collision
Collision occurs when the hash function maps two or more items (keys) with different search keys into the same bucket or index. There are two major schemes for solving the collision: separate chaining and open addressing.
- In chaining, if a hash function produces the same index for multiple elements, these elements are stored in the same index by using a doubly-linked list.
- Unlike chaining, open addressing doesn’t store multiple elements into the same slot. Here, each slot is either filled with a single key or left. For example, In linear probing, collision is resolved by checking the next slot.
Basic Algorithms
Sorting algorithms
-
Selection Sort: Repeatedly “selecting” the next-smallest element from the unsorted array and moving it to the front. The time complexity is O(n^2). In place.
-
Bubble Sort: Compare two elements from front to back, exchange them if they are in reverse order, repeat until the array is ordered. The time complexity is O(n^2), the best case O(n). In place.
-
Insertion Sort: Starting from the second element, inserting elements from an unsorted array into a sorted subsection of the array, one item at a time. The time complexity is O(n^2), the best case O(n). In place.
-
Quick Sort: Quicksort works by recursively dividing the input into two smaller arrays around a pivot item: one half has items smaller than the pivot, the other has larger items. The time complexity is O(nlogn), the worst case O(n^2). Not in place.
int partition(int array[], int low, int high) {
// select the rightmost element as pivot
int pivot = array[high];
// pointer for greater element
int i = (low - 1);
// traverse each element of the array
// compare them with the pivot
for (int j = low; j < high; j++) {
if (array[j] <= pivot) {
// if element smaller than pivot is found
// swap it with the greater element pointed by i
i++;
// swap element at i with element at j
swap(&array[i], &array[j]);
}
}
// swap pivot with the greater element at i
swap(&array[i + 1], &array[high]);
// return the partition point
return (i + 1);
}
void quickSort(int array[], int low, int high) {
if (low < high) {
// find the pivot element such that
// elements smaller than pivot are on left of pivot
// elements greater than pivot are on righ of pivot
int pi = partition(array, low, high);
// recursive call on the left of pivot
quickSort(array, low, pi - 1);
// recursive call on the right of pivot
quickSort(array, pi + 1, high);
}
}
- Merge Sort: Merge sort works by splitting the input in half, recursively sorting each half, and then merging the sorted halves back together. The time complexity is O(nlogn). In place.
void merge(int arr[], int p, int q, int r) {
// Create L ← A[p..q] and M ← A[q+1..r]
int n1 = q - p + 1;
int n2 = r - q;
int L[n1], M[n2];
for (int i = 0; i < n1; i++)
L[i] = arr[p + i];
for (int j = 0; j < n2; j++)
M[j] = arr[q + 1 + j];
// Maintain current index of sub-arrays and main array
int i, j, k;
i = 0;
j = 0;
k = p;
// Until we reach either end of either L or M, pick larger among
// elements L and M and place them in the correct position at A[p..r]
while (i < n1 && j < n2) {
if (L[i] <= M[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = M[j];
j++;
}
k++;
}
// When we run out of elements in either L or M,
// pick up the remaining elements and put in A[p..r]
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = M[j];
j++;
k++;
}
}
// Divide the array into two subarrays, sort them and merge them
void mergeSort(int arr[], int l, int r) {
if (l < r) {
// m is the point where the array is divided into two subarrays
int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
// Merge the sorted subarrays
merge(arr, l, m, r);
}
}
- Head Sort: Heap sort is similar to selection sort—we’re repeatedly choosing the largest item and moving it to the end of our array. But we use a heap to get the largest item more quickly. Not in place.
Heap
Heap is a very useful data structure with its operations efficient for sorting.
Heap is a complete binary tree that satisfies the heap property, where any given node is:
- always greater than its child node/s and the key of the root node is the largest among all other nodes. This property is also called max heap property.
- always smaller than the child node/s and the key of the root node is the smallest among all other nodes. This property is also called min heap property.
When using the heap, the following are the basic operations used:
- Heapify: Return a heap data structure given an input binary tree.
- Insert: Insert a new element.
- Delete: delete the selected element.
In C++, make_heap() can convert a range in a container to a heap. push_heap() is used to insert elements into heap. pop_heap() is used to delete the maximum element of the heap.
Example code:
// Max-Heap data structure in C++
#include <iostream>
#include <vector>
using namespace std;
void swap(int *a, int *b)
{
int temp = *b;
*b = *a;
*a = temp;
}
void heapify(vector<int> &hT, int i)
{
int size = hT.size();
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < size && hT[l] > hT[largest])
largest = l;
if (r < size && hT[r] > hT[largest])
largest = r;
if (largest != i)
{
swap(&hT[i], &hT[largest]);
heapify(hT, largest);
}
}
void insert(vector<int> &hT, int newNum)
{
int size = hT.size();
if (size == 0)
{
hT.push_back(newNum);
}
else
{
hT.push_back(newNum);
for (int i = size / 2 - 1; i >= 0; i--)
{
heapify(hT, i);
}
}
}
void deleteNode(vector<int> &hT, int num)
{
int size = hT.size();
int i;
for (i = 0; i < size; i++)
{
if (num == hT[i])
break;
}
swap(&hT[i], &hT[size - 1]);
hT.pop_back();
for (int i = size / 2 - 1; i >= 0; i--)
{
heapify(hT, i);
}
}
void printArray(vector<int> &hT)
{
for (int i = 0; i < hT.size(); ++i)
cout << hT[i] << " ";
cout << "\n";
}
int main()
{
vector<int> heapTree;
insert(heapTree, 3);
insert(heapTree, 4);
insert(heapTree, 9);
insert(heapTree, 5);
insert(heapTree, 2);
cout << "Max-Heap array: ";
printArray(heapTree);
deleteNode(heapTree, 4);
cout << "After deleting an element: ";
printArray(heapTree);
}
Others
Pointer and Reference
Similarities
- Pointer and reference both are the concept of memory. The pointer points to a piece of memory, and its content is the address of the pointed memory; the reference is the alias of a piece of memory.
Differences
- A pointer is an entity, while a reference is just an alias.
- There is no need to dereference
*when using the reference, and the pointer needs to be dereferenced. - The reference can only be initialized once when it is defined, and cannot be changed afterwards; the pointer can be changed.
- References do not have const, pointers have const, and const pointers are immutable.
- The reference cannot be empty, but the pointer can be empty.
Easy to Forget
x++increments the value of variablexafter processing the current statement.x+=i++;additoxthen increaseiby 1.++xincrements the value ofxbefore processing the current statement.x+=++i;increaseiand addi+1tox.- Array is passed by reference.
array = &array[0]. - Reference must be initialized using a variable of the same type.
- Enumerate example:
enum Suit_t {A, B, C, D};
const string Name[] = {"A", "B", "C", "D"};
enum Suit_t x = C;
std::cout << Name[x] << std::endl;
Engineering Problems
C++ Design Pattern
A design pattern is neither a static solution, nor is it an algorithm. A pattern is a way to describe and address by name a repeatable solution or approach to a common design problem, that is, a common way to solve a generic problem. Check details in the reference: C++ Design Patterns Reference.
C++ Object Pool
What is an object pool?
- Pools are somewhat similar to collections in a sense. A pool is a collection of a certain amount of water; a memory pool is a collection of a certain amount of allocated memory; a thread pool is a collection of a certain number of created threads. Then, the object pool, as the name implies, is a collection of a certain number of created objects (Object).
What is the object pool for?
- In a C/C++ program, if you have to use malloc/free (or new/delete) to create and destroy an object, it will cost a lot on the one hand and cause a lot of memory fragmentation on the other hand. Over time, the performance will degrade. At this time, an object pool is generated. You can create a batch of objects in advance and put them in a collection. Whenever the program needs a new object, it will be obtained from the object pool. Whenever the program uses up the object, it will be returned to the object pool. In this way, a lot of malloc/free (new/delete) calls will be reduced, which improves the performance of the system to a certain extent, especially in programs with frequent dynamic memory allocation.
What are the characteristics of the object pool?
- In general, object pools have the following characteristics:
- There are a certain number of created objects in the object pool.
- The object pool provides users with an interface to obtain objects. When users need new objects, they can obtain new objects by calling this interface. If there is a pre-created object in the object pool, it will be returned to the user directly; if there is no object pool, a new object can be created and added to it, and then returned to the user.
- The object pool provides users with an interface for returning objects. When users no longer use an object, they can return the object to the object pool through this interface.
More on it: Object Pool
Reference
- Problem Solving with C++ (8th Edition), by Walter Savitch, Addison Wesley Publishing (2011)
- https://www.geeksforgeeks.org/
- https://www.codeproject.com/Articles/570638/Ten-Cplusplus11-Features-Every-Cplusplus-Developer
- https://en.cppreference.com/w/
- https://www.geeksforgeeks.org/the-c-standard-template-library-stl/
- https://www.programiz.com/dsa